Consider, for a moment, your big corporate project that you work with every day. I know. It's huge. I see several of these projects on a constant basis. Maybe you have one big project with multi-modules. Maybe you have a more mature approach that splits up a very large project into several multi-module projects. Whatever it is, there's a chance that you also work in the kind of environment that has a huge build with hundreds of dependencies that spans tens of thousands of lines of code. Your build spends most of the day juggling dependencies, both internal and external
...and, the build takes forever the first time you run it. Correction, the build takes forever every time you run it because it is just that big, and because you have the sort of environment that demands you always check for snapshot updates. Welcome to the reality of using Maven on a very large-scale project.
What happens when a new programmer rolls up and runs the build for the first time? What happens every night when you clear a CI build's local repository? Maven downloads the Internet. That's what happens. No really, Maven downloads MBs of dependencies from a repository, and it does so one-by-one pulling dependency metadata, POMs, and binaries down from a repository. It makes hundreds (if not thousands of requests) back to a repository.
Wasting Time
I'd like to put forward the idea that this is a problem with the design of the tool. Maybe it wasn't a problem years ago, but it is today. I'm both busy and impatient, and I can see a better way. If the repository already has artifacts, metadata, and dependency information why not save some time. Maven (or Gradle or Ant or whatever your poison) should make a single request, passing in a collection of GAV coordinates and the repository should be able to calculate all of the dependency information sending back a compressed archive of everything a build would need.
This. I want this:

Making Maven more like Git
Let's look to Git as an inspiration for how Maven should work going forward. Git makes a single request to a server, the server bundles up everything Git needs, compresses it and then sends down an entire repository. Quick, no waiting for XML parsing on the client side, no pages and pages of "Downloading XYZ..." on your screen, just a simple status that updates you on compression progress and a single network interaction. Git does it right, Maven does it wrong. Let's fix it.
I shopped this idea around to a few people. Some of the responses have been positive, but a few people have had a strong negative reactions. ("This is unnecessary.") I really only care about this for selfish reasons. I have a large project, I don't really want to have to sit next to another new developer and apologize for Maven. In fact, on this same project we checkout a 300 MB git repository and it is fast as could be, then I have to show them how to run the Maven build... we start it and then we go for a long coffee break during which I apologize for Maven:
"Maven isn't like Git, it takes time to make those requests. Maven has to download POM files, artifacts, metadata. Then it has to create a bunch of dependency graphs and sort out conflicts. Once those conflicts have been solved it then has to go get all the artifacts. One by one. I apologize, listen, the coffee's on me, ok?"
The Difference: Latency is annoying.
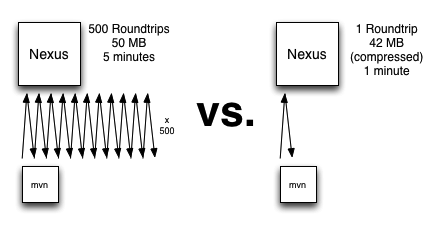
I did some quick metrics with a real project. Actually it is more like a megaproject. This project has an insane number of internal dependencies. Running the build with a prepopulated local repo takes approximately 3 minutes. Running the build without a prepopulated local repo (against a populated Nexus repo) takes approximately 11 minutes and it downloads about 120 MB of dependencies. That 7 minute difference is the download time (over a 100 MBps connection) plus the latency required to setup HTTP connections, parse XML, and calculate dependencies.
Think about that: it took Maven 8 minutes to calculate dependencies for all projects (and all Maven plugins) and then download 120 MB. All the files, all the POMs, all the metadata was already present in Nexus. Let's use a 120 MB download over a 10 MBps link to establish our baseline - if all we were doing was throwing this file down to the client, it should take ~10 seconds. I'm going to be generous and assume that it would take nexus 20 seconds to calculate all of the dependency information on the server-side (assuming that it didn't have to retrieve anything from a proxy repo). Let's them assume that compression of stream of files would add another 5 seconds of overhead.
This is where I'd like to go. Shift the calculation of all dependencies to the server side, send down an archive, and get rid of this back and forth between Maven and the repository. I think we can take this 8 minute Maven dependency mess and turn it into a 35 second process that involves 25 seconds of waiting and 10 seconds of transfer.
This should be easy, who's up for the challenge?
I think we can do this without having to muck with Maven. I'm not a big fan of the Maven codebase (it's a monster), and I'd rather not break into the tool itself. I think we could just write a simple CLI wrapper that would interact with a Nexus REST service. All this CLI interface would have to do is parse a pom.xml, gather a collection of dependencies and Maven plugins, and then send a request to Nexus. Nexus would then take this collection of GAV coordinates alongside the name of a single repository group to use for artifact resolution. Nexus would calculate the full list of transitive dependencies and then stream it back as a compressed collection of files to the CLI wrapper.
At this point, the CLI wrapper just unpacks everything and drops it in ~/.m2/repository. Maven would then run as normal, not even aware of the antics of what I'm calling "Maven Rides the Lightning".

Note, this is not my idea. Nambi Sankaran brought this idea up during a training class several weeks ago, and I very much want to see this happen. Nambi has created a Github repository for this project and if you are interested it would be a good opportunity to get some like minded people together and start thinking about how this could be done. Don't get too excited, there's nothing in that repo yet, but I know we have all the pieces available to make this happen. (Plus, I would really like to see some other people create a good open source Nexus plugin.)





