ABN AMRO is a bank in the Netherlands with a long history that goes back to the mid-19th century. In the last 25 years, we've grown digital channels that are greatly valued by our customers and have become the dominant channels. In 2015, The European Union set minimum requirements for European banks to open up checking account information via APIs to third parties via the PSD2 directive. ABN AMRO has gone far beyond these requirements by establishing a broader business-to-business API channel. We also set up an external developer portal to promote third parties to build on and leverage our financial services. Of course, this all needs to be backed by a well-organized internal IT organization.
The role of my department, Development Services, is to facilitate developers with Continuous Integration/Continuous Delivery (CI/CD) facilities that has to serve the developers requirements, regulatory requirements, and non-developer stakeholder requirements. In practice, this means assisting with development tools and supporting a number of specific platforms to create traceability and transparency, as well as related reporting.
The following article explains some of the starting points and how we envision supporting DevOps at an enterprise scale.
Article contents
- Centrally organized and product based
- The IT4IT data model
- Onboarding on tools
- Connecting the dots
- The solution in theory
- The current solution
- Technical realization
- Our future
- Challenges
- More by Fred Jonkhart
Centrally organized and product based
Over 10 years ago and in the midst of a merger, I was asked to look at the organization's support and development tools. ABN AMRO was still a project-oriented organization then, where Dev and Ops groups were separate. From past experience, it was already clear to us that the major tools, including version control, source code quality control, support for pipelines, and artifact management should be centrally managed. This to mostly satisfy non-developer requirements like traceability and the ability to centrally report. At least a minimum level of uniformity should be respected.
Another important choice was product orientation. Being confronted in the past with orphaned source code repositories after yet another reorganization, it was clear to me that organizing development data along organizational structures was not a good choice. Since what is being developed usually has a far longer life span than who is developing, a product-based approach was chosen.
Fast-forward to today and the organization is (being) transformed into a DevOps structure with around 400 development teams responsible for both development and operations. The tool support from just a few people 10 years ago has grown into Development Services, with over 200 people supporting much more. These include:
-
Software development standard and guidelines
-
All development-related tools
-
An internal and external developer portal
-
Code initialization based on design pattern
-
Standard building blocks for pipelines and template pipelines for commonly used technologies
-
Coaching on CI/CD
-
Hosting services for a number of vendor specific platforms and support for technology guilds
As part of the development tool, landscape Sonatype Nexus Repository has been used from the outset, followed later by Sonatype Lifecycle.
The IT4IT data model
What seemed to be lacking was a structural relation between the source code, development data, CI/CD data, and the service management data. With our product orientation, an administration grew around the development data, showing which applications were developed using which tools. This included Bitbucket, Jenkins, SonarQube, Fortify, Sonatype Lifecycle, and Sonatype Nexus Repository. In service management, an application portfolio was developed to support both the regular service management processes, as well as regulatory and enterprise architecture processes.
Simply put, we had two lists of applications that were not connected.
I also witnessed a recurring pattern where major lifecycle management and infrastructure projects made inquiries on application details. Every now and then, the development organization had to gather technical details into big Excel sheets to satisfy the data needs of those major projects or programs. At the end the project, the information was lost and the exercise was repeated in the next project. Our application engineering data was simply not available in a structured form, and inaccessible to stakeholders outside of development teams.
At the same time, the IT4IT initiative emerged in the market. This concept strengthening the idea that data within the whole IT value chain should be better defined to enable any scaled approach, whether being Agile-at-scale, DevOps-at-scale, or digital transformation-at-scale. One risk in agile and DevOps transformations is management losing visibility into what is happening.
An initiative was started to investigate how to implement an IT4IT model tuned for ABN AMRO.
Onboarding on tools
That many people still did not understand what were were developing was evident from the way we kept getting asked to onboard teams onto tools X, Y, and Z. Even after years of product orientation. A clear understanding of what you're developing (an application or another digital product) is a prime concern for organizing your engineering data.
In response, we developed a simple self-service pipeline. We'd we ask for a reference to an entry in the enterprise application portfolio, what acronym you want to use for your application, what technologies are required, and the person who functions as an administrator. The pipeline included a manual validation from our side, resulting in an environment to develop the specified application. This CI/CD environment initially included Bitbucket, Jenkins, SonarQube, Sonatype Nexus Repository, and most importantly our central LDAP that governed all the associated access groups. The technology question was required to initialize access to the appropriate repositories and paths inside repositories in Sonatype Nexus Repository.
With the introduction of Fortify and Sonatype Lifecycle, it became apparent that onboarding was required at another level. While our application portfolio assumes an application to be a complete solution, including all software and infrastructure, tools like Fortify and Sonatype Lifecycle look at the software / deployable units. We made some half-hearted decisions related to naming conventions that sort of linked the onboarded items to the overarching application. Onboarding SonarQube to the same deployable units was done automatically in the pipelines. If a scan result is offered to SonarQube with a yet unknown identifier, it created a new entry in the database on the fly.
These onboarding services were satisfactory only to a certain extent, and there were various drawbacks. First, due to having two separate application lists, a manual validation was required. This dramatically increased the average throughput time. People sometimes forget to enter the proper data, requiring corrections via request tickets, as well as manual corrections executed at the tool level. Sometimes we got requests for removing obsolete data, for which we did not have a solution at all and requiring additional manual actions.
At the request of management, another team in our department created dashboards on some CI/CD / DevOps metrics and code quality. For this, yet another administration was created to link teams, applications, and the software components. This application correlated and collected data from SonarQube, Fortify, and Sonatype Lifecycle.
Connecting the dots
The primary purpose of IT is to fulfill the company's business goals, but some of the concepts around IT4IT focus on the needs of IT. Some huge improvements are available in this process, with associated business goals.
Most development tools originate from a single team – single project situation, with enterprise support mostly shoehorned in as an afterthought. From a digital product perspective, the engineering data associated with a single product or a single component within a product is dispersed over many functionally-oriented engineering tools. There is no central administration that clearly identifies the digital products or the digital components. Nor does it cross-reference the associated engineering data in the tools in a consistent and technology-neutral fashion. There is also no structured insight in digital product composition at design time. We also lack understanding in the relation between operational configuration items and the engineering data they originate from.
Self-service facilities for development teams should not be limited to onboarding and instead must encompass the whole lifecycle of digital products and their components. These facilities should offer fully straight-through processing to avoid any unnecessary dependencies between development teams and teams that support the tools.
Looking from a value chain / supply chain perspective, it is even more important to understand the composition of the digital products we offer our customers. Its an illusion that a single DevOps team can be fully responsible for all the aspects of their product(s). From an agile position, total independence is the ideal, but at the enterprise level? It simply does not scale. And, in terms of human resources, it would be very expensive.
Knowing the product composition as well as the upstream and downstream dependencies is essential for doing agile or DevOps at scale.
The solution in theory
The essence of the solution is to know the portfolio of all enterprise digital products and the design-time composition of these products into each and every component. Not only software components, but any component including infrastructure, cloud resources, and what have you.
All involved items need to be uniquely identified and administered in the service administration, with each item cross-referencing the associated data in one or more CI/CD tools. With the registration, logical design items emerge where all the associated data elements should form a consistent and coherent unit.
In terms of the IT4IT reference architecture value stream, Strategy to Portfolio (S2P) results in the conceptual level of all digital products, both existing and to be developed. Each product has a clear ownership, and one or more teams can be involved in its development (for example, inner-source development also needs to be supported). Any item that is produced by one team and consumed by another is eligible to be a product in the portfolio.
In the Requirement to Deploy (R2D) value stream, all above mentioned items are identified and the engineering/tool data is added. Each conceptual product refers to one or more versions (releases), each version is represented by a Design-time Configuration Item (DCI). Each DCI has a decomposition into its components, where each component in itself can refer to another DCI. In other words, a tree structure emerges:
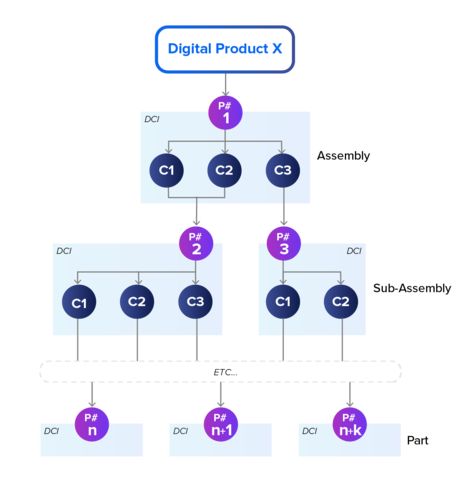
Process Flowchart
The DCIs are classified by a type and for each type, the mandatory data elements are identified (which implies mandatory tools). Then, the internal relations for these elements are identified. For example, root identifiers vs. derived identifiers.
For instance, Java components where the base identifiers are group id, artifact id, and version (GAV), are defined in the POM.XML file. In this case, for ABN AMRO-created components, additional naming conventions are applicable. The use of SonarQube, Fortify, Sonatype Lifecycle, and Sonatype Nexus Repository are mandatory. The identifiers for the associated objects in those tools are derived from the GAV.
Given both the conceptual level (product portfolio) with ownership and the engineering level (the DCIs), including the composition relations, the producer-consumer relationships emerge between teams.
This may all sounds still very theoretical, so let's get to the reality of today.
The current solution
To get started, we limited ourselves to one type of product, applications, and a small set of DCIs: only applications and software components. We also ignored multiple versions for now.
At the portfolio level, all the applications were already registered at the conceptual level (S2P), encapsulating the full lifecycle of an application. At the engineering level (R2D), roughly the following is done:
-
For existing applications, a corresponding DCI is created.
-
The following straight-through-processing application onboarding service is offered:
Create a CI/CD environment for a new application called <application acronym> -
For new homegrown software components, the following service is offered:
Add components <component list> to application <application acronym>
Note that "application" in this context is a complete end-user solution, including all required software and infrastructure.
For scenario 2, this means that a DCI record is created in the service administration, and any tool that the application requires to be onboarded will be touched. For example:
-
Application-specific access groups are created in the LDAP
-
Application-specific access paths in the appropriate Sonatype Nexus Repository repositories are created
-
Application-level access in SonarQube is created
The team members known in the service administration to own this application will be automatically granted access.
For scenario 3, this means that a list of new software components can be added, and for each software component, a SonarQube project, Fortify application, and Sonatype Lifecycle application are all created. Additionally, a new new DCI record is created in the service administration. Again, the appropriate access is granted for the correct team members to the newly created items.
The service administration now holds DCI records for both applications and software components, as well as the relations between parent DCIs (application for now) and their child DCIs (software components for now). The parent DCIs refer to the application portfolio administration.
Each DCI registers:
-
It’s identifiers
-
Other required input from the user
-
Which tools are onboarded
-
The onboarding status
As such, by using conventions, the associated engineering data in the tools can be found by any stakeholder in the company for a given digital product.
Technical realization
The architecture of the solution should support all CI/CD tools in use by ABN AMRO. All CI/CD tools are managed in one department by several teams, where each team is responsible for several tools. Therefore, the architecture has two distinct layers: a central service that exposes an API to be consumed by client processes.
For each tool, there is a specific service that translates the API expected by the central service into tool-specific API calls. Each tool service translates our IT4IT operating model, as represented in our service administration, into tool-specific concepts and vice versa. For example, we request to both the SonarQube service and Sonatype Nexus Repository service: Create a CI/CD environment for a new application with a given name. For both SonarQube and Nexus Repository Manager, this request means different things. For SonarQube, 16 API calls are made based on this one request.
Currently, we have implemented one client process and two request forms on our intranet for the two aforementioned services. The forms filter picklists based on team membership and application ownership, as known in the service administration. From a technical perspective, each service is implemented as a container and deployed on the same k8s (Kubernetes) cluster.
Three teams are now involved in delivering these services, which span the larger half of the ABN AMRO CI/CD tools.
Our future
We got a pair of requests for two new client processes. One was a very specific refactoring case to support the conversion of old components into new ones (old tech → new tech). The other asked for CI/CD metrics service (mentioned earlier) to enable metrics based on the central service administration instead of their own administration.
We are also working on implementing the sunset phase of the application lifecycle. When applications are decommissioned, we want to remove access to all tools while preserving the CI/CD data for a retention period. The naming for this archive service is service is "archive application <application acronym>."
In addition to the archiving effort, we are creating an un-archive service to restore access based on the relations in the service administration (team(s) → owned applications → components). A future service will be built to remove the data from all tools at the end of the retention period.
Finally, we are looking at how to identify existing DCIs from the existing CI/CD data. We believe that tapping in on builds is probably a good solution. Observing build events (what things are built) and comparing those events with the registered DCIs will identify the missing DCIs that are built on a day-to-day basis.
Challenges
This solution has the following dimensions resulting in potentially many items to be managed:
-
The tools involved.
-
The types of DCIs involved.
-
The data elements associated with each type, the standards and guidelines, and applied conventions required.
For the solution to work, clear standards and guidelines are required for each DCI type. At a minimum, the basic naming conventions and the mapping to the core tool objects need to be clear.
Adding either a tool or adding a type requires the relationships between them to be assessed. Does this type have some data in this tool? If so, are there agreements on how to initialize that data? etc.
For example, with Java components in combination with git, there can be several choices. Assume you have no agreement on the source code location for Java and allow several options (mono repo, repo per application, repo per component, etc.). Then, just ask for the POM.XML location and register that (no convention, just declaration). The alternative is having an agreement on a convention and assume the POM.XML location (using convention over declaration).
If an agreement can be reached, a next step could be not only to validate what is offered but to apply a template to create an initial file and folder structure. Adding more details in the standards and guidelines is always a prerequisite for further automation.
The biggest challenge is probably that coming to such agreements is an organizational challenge, and such things take time.
An important technical challenge is the implementation of validation. Adding a new type by hard-coding it will not scale. Some data-driven solution is required. Maybe a JSON schema or something similar, but we have to decide.
Last but not least, applying such a structured approach should not stifle innovation. The solution should have some flexibility and allow maneuvering space without dropping the ball by losing control.
More by Fred Jonkhart
-
Does DevOps needs a data model [Medium], Mar, 11 2021
-
The missing link in IT management product design time configuration management [Medium], Apr 16, 2021
-
Design-time configuration items [Medium], May 19, 2021
-
Digital product composition [Medium], Aug 26, 2021