
Effective vulnerability management is a major task for development teams, and knowing what problems to prioritize can save unnecessary re-work. In the software composition analysis (SCA) community, a hotly-debated approach to prioritization is vulnerability reachability, also known as "call flow." Today, we take a look at why vendors argue for or against analysis of reachability.
Article contents
- Requirements
- What is the right solution?
- What if I have to pick between data quality or prioritization?
- Conclusion: Aim for better data
First, there are the minimum requirements to estimate static reachability:
-
Static analysis of program behavior
-
Specific vulnerability signatures
Static analysis without vulnerability signatures won't help you find Common Vulnerabilities and Exposures (CVEs) in third-party code. Signatures without precise static analysis will result in inaccurate and misleading prioritization guidance.
Also, since no developer or security expert wants to wait anywhere from 30 minutes to several hours after a source code change to find out something is vulnerable, speed is also a consideration. Our full requirements list is therefore:
-
Accurate vulnerable method signatures
-
Precise static analysis
-
Efficient (fast) analysis
Let's dig into what is required to achieve (or not achieve) each.
Requirements
1. Accurate vulnerable method signatures
This is the cornerstone of vulnerable method detection. Without research on the source code to determine the specific vulnerable method, accurate results are impossible. Further, no public database specifies the method call or configuration settings that enable the vulnerability.
Getting accurate signatures requires:
-
The fix commit: This is the source code that was changed in order to correct the vulnerability. This identifies the method(s) that must be called in non-fixed versions to exploit the vulnerability.
-
The introduction commit: This is the source code that introduced the vulnerability. In many cases, a disclosure will incorrectly say that it applies to all previous versions, including those older versions where the vulnerable code was not yet introduced.
-
The relocation commit(s): Because source code changes can happen over time through refactoring and component name changes, the true introduction version and exploitable method are often missed. It's therefore important to follow the exploit through these changes.
Failure to perform step #1 accurately can lead to vulnerable methods being missed or the inclusion of methods not involved in the actual vulnerability (false negatives and false positives, respectively). Not performing step #2 can result in too many versions of the library being tagged as vulnerable (leading to false positives). And if step #3 is not performed correctly then versions that ARE vulnerable can end up tagged as non-vulnerable, leading to false negatives.
These core "data quality" issues can cause unnecessary re-work and leave applications vulnerable, whether or not reachability-based prioritization is used. With reachability-based prioritization, data issues combine with inaccuracy in static analysis (see below) to further amplify the noise produced by an SCA tool.
2. Precise static analysis
Performing static program execution analysis to look for vulnerabilities is often shorthanded as "static analysis." The technology looks at source code (or in rare cases, binary code) to determine potential security risks. Static analysis has some restrictions, including:
-
Limited understanding of:
-
The exploit surface – what causes the exploit to occur.
-
The attack surface – where the attack enters the applications.
-
The "air gaps" – places where a reachability relationship can exist but that relationship is not clear from the source code (e.g. RESTful calls or dynamic method invocation). This is a huge source of missed vulnerabilities (false negatives).
-
-
Overapproximation – Language features like polymorphism and dynamic dispatch are often overapproximated in order to improve analysis times, resulting in false positives.
-
Resource-intensive – Accurate whole-program reachability is computationally expensive, which is why most tooling does less precise analysis of libraries and over-approximates certain language features.
The complexity of traditional application security analysis increases when you consider third-party, open source libraries. Because of computation complexity, the analysis generally stops at the library boundary. So even if you had a lightweight static analyzer to cover all your bases, it is still only looking at the standard attack/exploit signatures. As a result, you'll still need the vulnerable library signatures.
Below, program calls are replaced with open source frameworks and libraries:
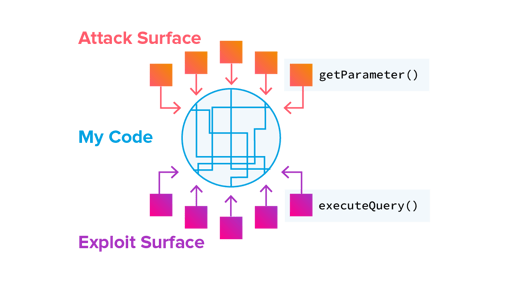
We end up with a complex branching set of sub-systems where each library is essentially a separate application. The lines inside the blue circles are execution paths.
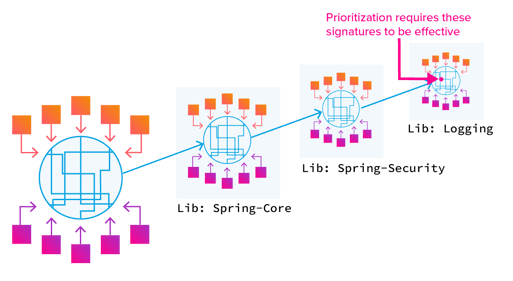
Now you're doing that same static analysis on each of those applications. Those third-party libraries are themselves an additional program, making all the flaws of static analysis become exponentially worse.
That's what you're asking from prioritization.
It's also important to note that the vulnerable method (line inside one of the sub-nodes) is not a traditional attack surface or exploit surface, and therefore would be missed by traditional static analysis without detailed data.
While these are all known and generally agreed-upon as standard barriers, some of the more mature vendors will have at least partially solved these problems. Unfortunately, these solutions come at the expense of performance. The analysis results must typically be less complete to remain timely.
3. Speed of analysis
Performing thorough program execution analysis of the first-party code base is not performant and this is generally an accepted attribute of static analysis. It is also widely understood that only 20% of the code base is first-party code. Combining exhaustive analysis of the open source libraries with the first-party code base just takes too long.
What is the right solution?
Unfortunately, no technology currently exists that can tell you whether a method is definitively not called, and even if it is not called currently, it's just one code change away from being called. This means that reachability should never be used as an excuse to completely ignore a vulnerability, but rather reachability of a vulnerability should be just one component of a more holistic approach to assessing risk that also takes into account the application context and severity of the vulnerability. The "prioritization" mindset of using static analysis to determine which vulnerability to fix first is not wrong, however high-severity vulnerabilities should always be fixed regardless of their current estimated reachability or position in the dependency tree.
It's also important to understand that prioritization is often used to hide the fact that many SCA vendors have low quality vulnerable component identification. Many vendors use the National Vulnerability Database (NVD), Common Platform Enumeration (CPE), and other advisory identifiers, which give a starting point for SCA capabilities but are prone to various inaccuracies. These public advisories may have incorrect information due to fuzzy matching of vulnerabilities to components, imprecise lists of affected version ranges, and inconsistent use of the Common Vulnerability Scoring System (CVSS) severity system.
When accurate static analysis is coupled with high-quality vulnerable library data, it's possible to get useful guidance for remediation activities via prioritization based on reachability. We currently support this via our partnership with Micro Focus' Fortify software, as well as in a prototype solution for non-Fortify customers.
What if I have to pick between data quality or prioritization?
As noted above, Sonatype believes there is value to reachability-based prioritization coupled with high-quality vulnerability data. However, for those situations where you have to choose just one, reachability-based attempts to filter out the noise are less effective. You're usually better off drawing from high-quality data and not prioritizing based on reachability.
To illustrate this, suppose your SCA tool has 100 vulnerabilities in its database. These apply to open source libraries in active use within your applications. Our experience has shown two possible outcomes:
Scenario A
Reachability-based prioritization with low-quality SCA data.
The tool looks at the library versions you're using and the versions it thinks are vulnerable and decides that 40 of the vulnerabilities apply to your codebase. As a result, the tool reports 40 vulnerabilities. With imprecise information on which library versions are vulnerable, 20 of those reports will not actually apply to your codebase, meaning these 20 reports are false positives. Poor detection of what components are in your codebase results in another 10 vulnerabilities that should be reported but aren’t (false negatives). These result in 10 vulnerabilities missing from the reports.
Reachability analysis is then used to prioritize the delivered reports. This output explains that, of the 40 reported vulnerabilities, 20 of them have reachability and should be prioritized.
If you fix the prioritized reports, and we assume false positives and true positives are equally likely to have reachability, then you will end up with:
-
10 fixed false positives (wasted work)
-
10 true positives (good!)
-
10 missing vulnerabilities because they weren’t prioritized by reachability analysis
-
10 vulnerabilities because the tool has so many false negatives
The result? You'll have fixed 20 "issues" but only remediated 10 real vulnerabilities. And another 20 real vulnerabilities have gone unremediated.

Scenario B
Your SCA tool has high-quality data but does not perform reachability-based prioritization.
Now you get 30 reports and all of them are true positives. Under our assumptions above, 10 of these might not have reachability, but that doesn't mean they aren't real issues that should be addressed (see the section 2, "Precise static analysis," above on the limitations of static analysis). Even if you randomly pick 20 of these 30 issues to remediate, you are guaranteed to be better off from a risk perspective than Scenario A.

The result is a lower signal-to-noise ratio and better overall results.
Conclusion: Aim for better data.
People want prioritization because they have too many results, but constantly prioritizing things that are already built-in doesn't make up for poor data. Although reachability-based prioritization can help plan remediation work, it will only amplify the effort and false sense of security that comes from inaccurate vulnerability matching.
Optimal reduction of open source risk starts with high-quality component data that includes more than just vulnerabilities and provides visibility into quality, hygiene, etc. Better data means cleaner results earlier on, and less of a mess to clean up down the road. And since accurate SCA solutions like Sonatype already exist that are based on high-quality, manually researched data, no one should accept a lower bar for open source risk.
Credits
- Co-author: Bruce Mayhew





