More entries in this series: Part 2, Part 3
Part 1: Understanding the software supply chain
In 2021, the world suddenly came up to speed on the scale and impact of open source software. While many outside of tech had never heard the tales of software eating the world, the wide usage of the open source Java logging library, Log4j, changed all that. And for the months that followed the end of 2021, it became the type of conversation you had with your parents when trying to troubleshoot their computer issues remotely.
Family tech support aside, the incident represented yet another piece (if not the biggest to date) used to spark direct government involvement since the Cyber Security Executive Order in May of the same year. As tends to be the case, businesses everywhere have scrambled and continue to do so, trying to understand things like open source security, the software supply chain, and what a software bill of materials (SBOM) is.
These are new concepts to many, even companies that have deployed solutions to address these areas. But this isn’t a new problem; many industries have faced the challenge of sourcing high-quality parts (open source components for tech).
Over the next three blog posts, we’ll look at how modern supply chains manage problems (and how others can learn from their mistakes). We’ll also help you better understand the evolving landscape of software vulnerabilities and attacks. Finally, we’ll look at the responsibility software organizations (i.e., every business on the planet) have in addressing and mitigating risks associated with the software supply chain.
Software supply chains are enormous
When we look at the scope of open source software consumption, it can be nearly impossible to understand how vast it truly is. There are billions of downloads each year, and soon there will be even more.
As part of our dedication to ensuring open source component availability, Sonatype runs the Maven Central repository. Most know it as the place where the world sources its open source Java components. And last year, we saw over 497 billion downloads. This year we're on track for nearly 700 billion downloads.

It’s not just Java experiencing massive growth. If we look at JavaScript and other languages, we see the same trends.
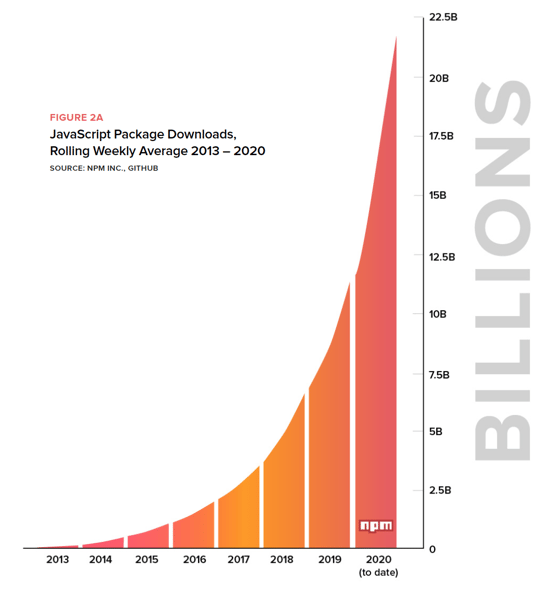
Across all the ecosystems, there are massive numbers of new projects and new versions of projects, adding up to a staggering number of choices for developers to wade through and track.
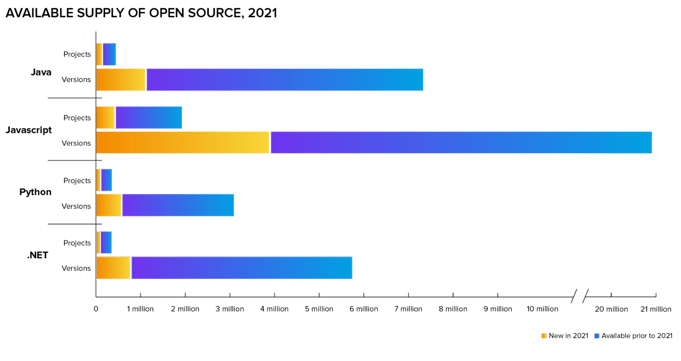
Considering the hard work and investment that goes into open-source projects, it shouldn't be surprising that we're building on top of the shoulders of giants.
Today, no one will create or reimplement UI frameworks from scratch. Instead, you choose a well-known and trusted framework (hopefully one with frequent updates) and build your business logic on top of that. The net effect is that now we source and assemble pre-existing components into our applications. Effectively we’ve created a software supply chain.
This efficiency can be helpful, but it can also come at a cost. Our projects now use parts. Rather than relying on building these parts ourselves,, we can look to suppliers. We no longer have to reinvent parts from scratch or make the same mistakes that come with building something new.
Of course, thinking of open source in the paradigm of supply chains can be new for some.
How to improve and secure your software supply chain
Before we talk about how we can improve and secure those supply chains, it is helpful to think about physical supply chain practices.
Modern software supply chain theory owes much of its success to W. Edwards Deming, who helped the Japanese auto industry rebuild after World War II.
While Deming provided much thought leadership in this area, we can focus on a few key points:
- Source parts from fewer and better suppliers.
- Use only the highest quality parts, and don't pass defects downstream.
- Continuously track the location of every part.
It should be no surprise that the software industry currently struggles with the last one the most.
If we think about what was at the heart of Deming’s guidance for the automotive industry (and what we take for granted today), here’s how that looks for software:
- Don’t have fifteen different components/frameworks for the same function (source parts from fewer and better suppliers).
- Only use the best version of those projects (use only the highest quality parts).
- Have a software bill of materials to track what's going on inside your applications (continuously track the location of every part).
The last one is more popular today than ever and will help you get a handle on the first two points.
To help frame this problem in a way that highlights how the software industry can improve, we can relate this to challenges in physical supply chains. Here are two stories that mimic software supply chain challenges.
The Chevy Cobalt
In 2014, an issue with the ignition switch became widely known. If you had a heavy key chain and it pulled the ignition switch, the car would shut off. This caused the driver to lose power steering and power breaks. But worst of all, safety systems like airbags would disable after only a few seconds.
The investigation found the pressure required to turn the ignition from run to accessory was very low in some switches. While the engineers had found and fixed the problem, they didn’t rev the version number. In other words, the fixed parts shared the same identifying version number as the originals.
This pattern should be very familiar to software developers. It often manifests with someone saying, “Well, I don’t know, it works on my machine.”
In this instance, the net effect of a configuration management error protracted the investigation because they took parts off the shelf, tested them, and they tested OK. When they finally understood what had happened, they realized fixed vehicles could be using the defective parts because the part number was the same. Subsequently, they had to recall all 2.6 million vehicles to ensure they had repaired them correctly. Not to mention litigation and claims against GM that followed.
E.coli outbreaks attributed to contaminated lettuce
Just a handful of years ago in the US, it seemed like we had a massive E.coli outbreak related to lettuce every year.
In the US, about 70% of lettuce is grown in California. Another 20% is produced in Arizona and Florida. Where the lettuce is grown depends on the season, with summer and fall growing seasons associated with California and winter for the other locations. In one instance, the outbreak occurred after the growing season had moved from California to Yuma, Arizona. The cause of the tainted lettuce turned out to be an infected irrigation canal that impacted 23 farms.
Like the Cobalt issue, this created a challenge when trying to figure out the actual root cause of the problem. After multiple years of outbreaks and many investigations by the FDA, the result was a purge of leafy greens from the market and no concrete answers. Finally, in 2018, the FDA strongly recommended the lettuce industry start labeling the lettuce with the region and the farm of origin. While E. Coli outbreaks still occur, they can quickly trace it back and recall the affected lettuce.
As consumers, we all expect these things from our physical goods manufacturers. We would laugh an auto manufacturer out of business if they decided to stop having recall capabilities. Yet we somewhat tolerate that exact condition in the software we all produce.
When will the same standards apply to software development?
Part of this is because consumers just haven’t been aware of how poor software supply chain best practices are creating the issues now rising to public forums. As we mentioned at the beginning of this post, software vulnerabilities weren’t part of the general public’s lexicon until 2021.
Today, that’s changed dramatically, with governments and media leaning in to set standards and expectations for today’s businesses. But what about everything that preceded Log4Shell? What can we learn from the past, and what are attackers doing today?
In our next post, we’ll deconstruct some of the most well-known attacks on the software supply chain and learn how attackers evolve their approach.
Editor’s note: This article was co-written by Jeff Wayman. Read more about open source from Jeff, or connect with him on LinkedIn.
.jpg)