
Previous entries in this series: Part 1, Part 2
This series started with a discussion on how open source software has shifted software development to rely on a supply chain. And how existing supply chains respond, improve, and adapt to make mitigating and remediating unexpected issues easier.
In our second post, we looked at how the software supply chain has been under attack for nearly a decade. But while some attacks have stayed the same, others are evolving. We identified three key phases.
- The Zero Day
- The Supply Chain
- The Corporate Developer
In each phase, the attacker targets similar outcomes. However, approaches have expanded to include and, to some degree, concentrate on developer infrastructure and the developers themselves. The consequences of these attacks aren’t just financial; we can attribute cost and collateral damage as an actual risk to human lives.
When lives are on the line, the stakes are raised. It also presents a critical question and brings us to the focus of our third and final post: who’s responsible, and how do we minimize the impact on developer efficiency and speed?
Views on open source can be misguided
To understand current thinking, look to the introduction of items like the Executive Order here in the US and similar initiatives from governments worldwide. These have both engaged the media and raised awareness among organizations and consumers.
The results? A collective panic.
Without overstating the reaction, there has been an immediate over-rotation towards issues with open source and a perceived lack of funding. Many involved inappropriately think of open source volunteers as amateurs.
At present, you don’t need to travel far to hear chants of “the federal government must get involved and provide funding.” And in at least one overheard conversation at a holiday dinner table, “Can you believe the Internet is running on free software?”
Oh no, the humanity, right?
Nope.
Open source software might be free for others to use, but in some cases, it takes literal rocket scientists to build.
These views and statements about amateurs building open source are inaccurate and misguided. Even worse, they trivialize the work being done. Without highly trained experts in open source, we’d never see projects like JPLs F Prime, which is behind the flight architecture for missions to Mars, or achieve the advancements from projects that build the foundation of the Internet.
The people working on these open source projects are professionals who want nothing more than to continue working on fun code during their free time. In many cases, they have tangible goals to leave behind a legacy more significant than their “day job.”
Unfortunately, most current proposals fixate on targeting open source. Suggestions include fixing the contributions, helping the maintainers do a better job via code audits, using automated code scanning and analytics tools, and providing better signatures. And these are just a few. But to truly understand how to solve this problem, we must consider where the responsibility lies.
Where DOES the responsibility lie?
Let’s look at the auto industry again.
Today manufacturers are taking a two-prong approach to improve the quality of parts coming out of their supply chain.
First, they print a list of all the components in a vehicle, place it in the glove box, and then ship the vehicle. This way, every car owner will know exactly which parts are in their car. If there’s a problem, they can reference that list and coordinate with the manufacturer.
Next, because they want to make sure those producing the parts for their supply chain produce the highest quality parts, they make sure those suppliers are paid more.
Wait, none of that is true, yet this is at the heart of how many believe the software supply chain should be managed.
To understand how auto manufacturers are actually solving this problem we can look back to the incident with Takata airbags and the corresponding recall. The recall of the affected parts was possible because the manufacturer had a bill of materials that could be linked to individual cars produced. This is true even though they may have multiple suppliers. For consumers, this meant that even if they didn’t own the car during the recall, Takata could identify their vehicle as one with a compromised part later down the line.
If Takata’s recall had operated more similarly to how many organizations that don’t use SBOMs respond to open source vulnerabilities, they would not have been unable to track the dysfunctional parts or issue a recall.
In supply chain circles, what Takata did was an intelligent recall. In our first post, we talked about lettuce recalls, and how they had to remove all lettuce from the shelves of grocery stores until they could effectively track contaminated products. Again, it comes down to ensuring that you have the proper perspective regarding responsibility.
For development teams, responsibility means helping them make better choices. Choose better, more stable components on the front end. This should sound very close to one of Deming’s principles we discussed in the first post of this series. You won’t be able to perform a recall and manage your response without an organizational software bill of materials.
Unfortunately, consensus can take a lot of work to build. To help illustrate the struggle developers face when making better choices, we looked at vulnerable downloads from Maven Central as part of our latest report on the state of the software supply chain. For 95.5% of the projects downloaded, there was a fix available.
On the other side, only 4.5% of vulnerable components downloaded from Central represented a scenario where maintainers needed to fix or had not fixed an issue fast enough.
Let's look at that another way. This means consumers were “choosing” the vulnerable version 95.5% of the time when a better choice was available.
We don’t need to fix open source. It’s the inverse. Consumers of open source need to be enabled and informed to understand their choices. In other words, developers must take responsibility for the parts they’re using.
And this is something Sonatype has been working on since our inception. Our tools provide information to developers, security professionals, and organization leaders to make informed choices about the component they use.
How is the software industry doing overall?
Over the past eight years, we’ve been surveying companies to understand organizational approaches to dependency management better.
A few years ago, we reached a milestone where about half of those companies indicated at least some process to manage their dependencies. And 37% of them had automated tooling to do it.
This is great because these numbers were in the teens when we started this survey. For the pessimists among us, no one would feel comfortable buying a car or consuming a food product if only half of the parts or ingredients used to produce them were known to the manufacturer. This would be especially true if only 30% of the companies producing them could conduct a recall.
We know this because no one thought getting sick from contaminated lettuce was okay. And in the wake of being unable to identify the contaminated products, the response was to throw all of it out.
When it comes to the software supply chain, this is where we find ourselves today.
Now, we’re a vendor, right? So you’d expect us to tell you that you can make a real difference with the proper tooling (ours) combined with improved processes and best practices (based on lessons from supply chains).
We believe that to be entirely true. But instead of simply taking our word for it, let’s look at the data.
In the wake of the Log4Shell vulnerability, Sonatype started conducting detailed analyses related to customer response. We had examples of companies with tooling in place and could compare how quickly those companies could identify vulnerable components and improve component choice.
In a specific case, a customer from the financial industry had more than 4,000 applications potentially impacted by Log4Shell. The image below shows they remediated one hundred percent of their portfolio in under a week.
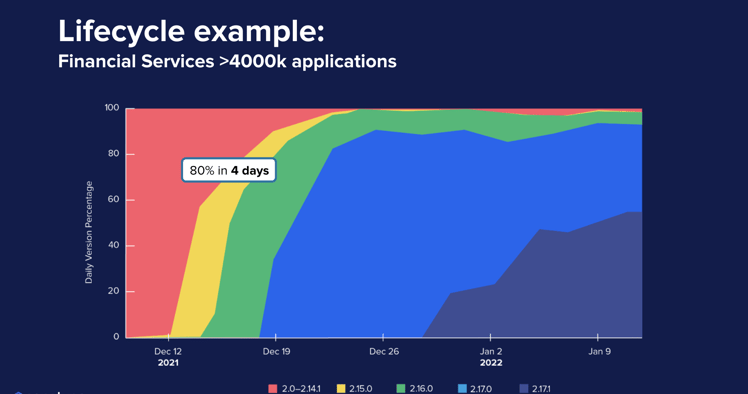
Let’s compare that to the data we covered in our previous post, where nearly 25% of consumers are still downloading vulnerable versions of Log4j today.
We can even draw direct parallels showing companies with tooling in place (purple line) and those without (red line).
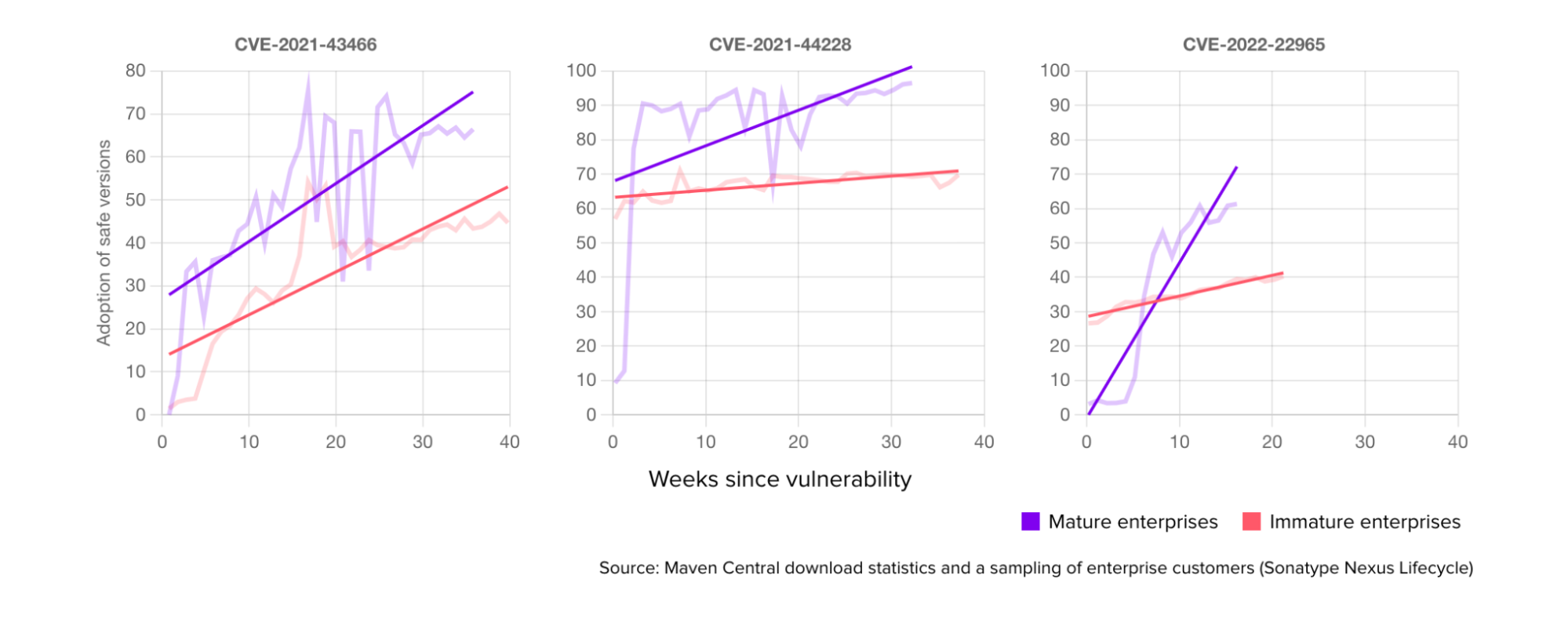
This distinguishes the difference between those prepared for this problem and those not. Put simply, proper tooling, best practices, and processes can impact outcomes and trajectories for the efficiency and resiliency of your business.
Who is responsible for preparing businesses to handle open source properly?
As a thought experiment, imagine you learned there was an imminent vulnerability with a specific open source component. And this is a reality we deal with every day. A couple of months before this post, we had that scenario with a OpenSSL vulnerability of unknown impact.
Could you right now, not in a day or week, without a doubt answer these questions:
- Are you using this exact component, and in which applications?
- Can you track the remediation across that portfolio?
- How long will it take you to ship and deploy an update?
If you have tooling in place, you already know this is a non-issue. But everyone should be prepared to handle issues in the same manner that Takata dealt with the airbag recall. If your response looks more like the Chevy Cobalt or tainted lettuce scenarios, there’s a problem.
Of course, this works when we know there is a vulnerability. But what about malicious packages and attacks with an approach like dependency confusion?
There’s tooling for this available today as well. And if you don’t have a solution, you should be concerned about how you will avoid the next malicious release. Because if you can't even deal with the latent bugs in the code you're already using, how will you deal with code designed to steal things and harm your developers the moment they download it?
If we consider it in the context of factory terms and the principles from Edward Deming, traditional application security practices only focus on protecting the output.
If you've designed an application security approach focused solely on what's coming out of the software supply chain, you're missing half the battle.
Identifying a known vulnerability will not always solve the problem. In many cases, the situation gets missed because developers accidentally download the wrong component without realizing it. They might fall victim to typosquatting and download a vulnerable component that uses an underscore when the actual version they wanted uses a dash.
Many of these components don't even compile when it comes to malicious packages. And what happens when it fails to build is the developer realizes their mistake, they fix it, and check it in. Even if you have supply chain tools capable of analyzing the component, you’ve missed the actual attack.
What that approach and those tools don't see is that the moment the developer downloaded the package, it was malicious, and now they have suffered a backdoor attack with nothing to sound the alarms.
How do you defend against that?
There are techniques, and as we’ve mentioned, Sonatype provides solutions to address them. But while important, not enough people are focused on solving this issue.
Software development can be both secure and fast
Conventional wisdom tells us that focusing on security is important, and it is worth the trade-off to speed. In fact, in most circles, heads will nod in agreement. But it doesn’t have to be that way.
In 2021 we decided to challenge the perception that you must sacrifice speed for security with another study. We looked at different companies' practices and put them into different categories.
On the top left of the image below, you have companies focusing on security above all else. On the bottom right are companies focused on shipping things as fast as possible. And then, in the top right quadrant, you have companies doing both.
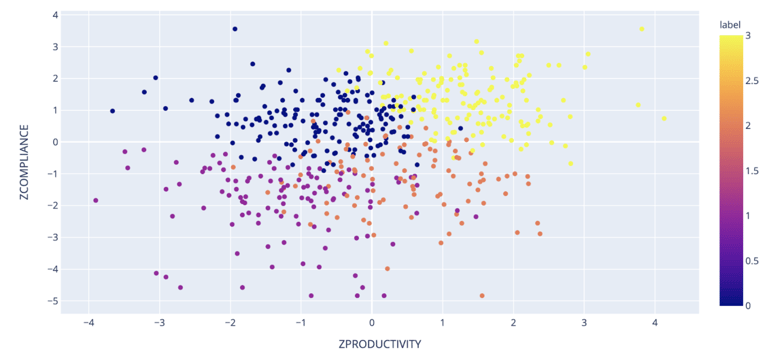
Our study found that the highest performers were faster than those who only focused on speed and more secure than those who only focused on being secure.
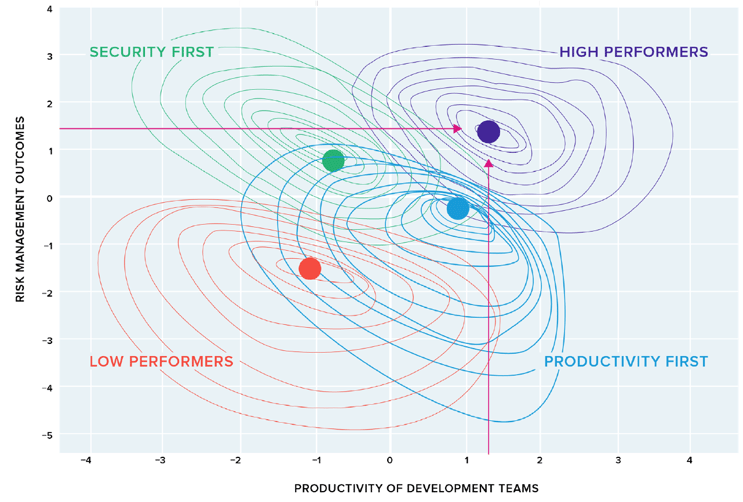
This might seem counterintuitive until you stop and think about it. The companies only focused on going fast don't get the luxury of ignoring Log4Shell or other problems of that scale. They still have to fix it.
What it means is that they are entirely unprepared to do so. And that becomes unplanned work, immediate technical debt, and a range of stuff they need additional time to resolve. This kills their performance.
In contrast, organizations that have accepted that better security means teams will move more slowly often ignore opportunities to innovate and improve speed. They’ve accepted what they believe is a realistic cost and dismissed the possibility of both.
With this in mind, we have designed and evolved our solutions to these challenges for over a decade. As a result, we believe it’s possible to be secure and fast.
Through our stewardships with programs like Maven Central, our sponsorship of the Open Source Security Foundation, and the academic research and reporting found in the State of the Software Supply Chain report, we are working to help the industry realize they can have both.
And things can get even better.
Sonatype provides tools that enable everyone involved in solving this problem to have increased insight into components entering the software supply chain. In addition, these same tools allow developers to make better choices and decisions when choosing components. Our tools also offer protection to automatically defend your organization from the evolution of attacks like those done through dependency confusion and malicious package techniques.
You don’t have to wait for governments to solve this problem. You don’t have to wait for the world’s entire development workforce to be better trained, and you don’t have to wait for open source projects to offer more/better pay. Solutions to all these challenges exist today.
The question we leave you with now is rhetorical. Do you want to maximize your organization for security and speed, or do you want to ignore responsibility for your software supply chain and risk managing your next recall like tainted lettuce or faulty ignition switches? The choice is yours.
Editor’s note: This article was co-written by Jeff Wayman. Read more about open source from Jeff, or connect with him on LinkedIn.
.jpg)




